
Using IMDb as a Test Data Set
Table of Contents
1. Background


IMDb (the Internet Movie Database) provides a set of files containing a core subset of its data for movies, TV shows, actors, crew, and related entities.
I needed a reasonably large data set to support some technology evaluations I was doing - and this seemed like a good fit. In this post I will describe how I first transformed the raw IMDb data and then loaded it into a relational database (actually, two databases - H2 and MySQL).
The data is provided in a set of files here:
At the time of writing the files are:
-
name.basics.tsv.gz
-
title.akas.tsv.gz
-
title.basics.tsv.gz
-
title.crew.tsv.gz
-
title.episode.tsv.gz
-
title.principals.tsv.gz
-
title.ratings.tsv.gz
A brief overview of their contents is provided here:
https://www.imdb.com/interfaces/
They also clarify the limitations on how this data can be used:
Subsets of IMDb data are available for access to customers for personal and non-commercial use. You can hold local copies of this data, and it is subject to our terms and conditions. Please refer to the Non-Commercial Licensing and copyright/license and verify compliance.
The raw uncompressed data files contain approximately 6.2 million titles and approximately 9.6 million people, who I shall refer to as “talent” - meaning actors, directors, producers, and other cast & crew members.
A Warning about the IMDb Data Set: The data contains movies and videos for adult content titles. You can filter these out using the is_adult column in the title table. Do not use this data, or present it in demos, if that content may cause offense. Which it probably will. How you censor the data is up to you - but always be respectful of your audience.
2. Data Model
Looking at the overview (linked above) you will see that there is a fair amount of denormalization in the source files. I will re-arrange this data into structures more closely resembling a 3rd normal form relational schema - not exactly - but most of the way there. We will end up with a data set looking like this:
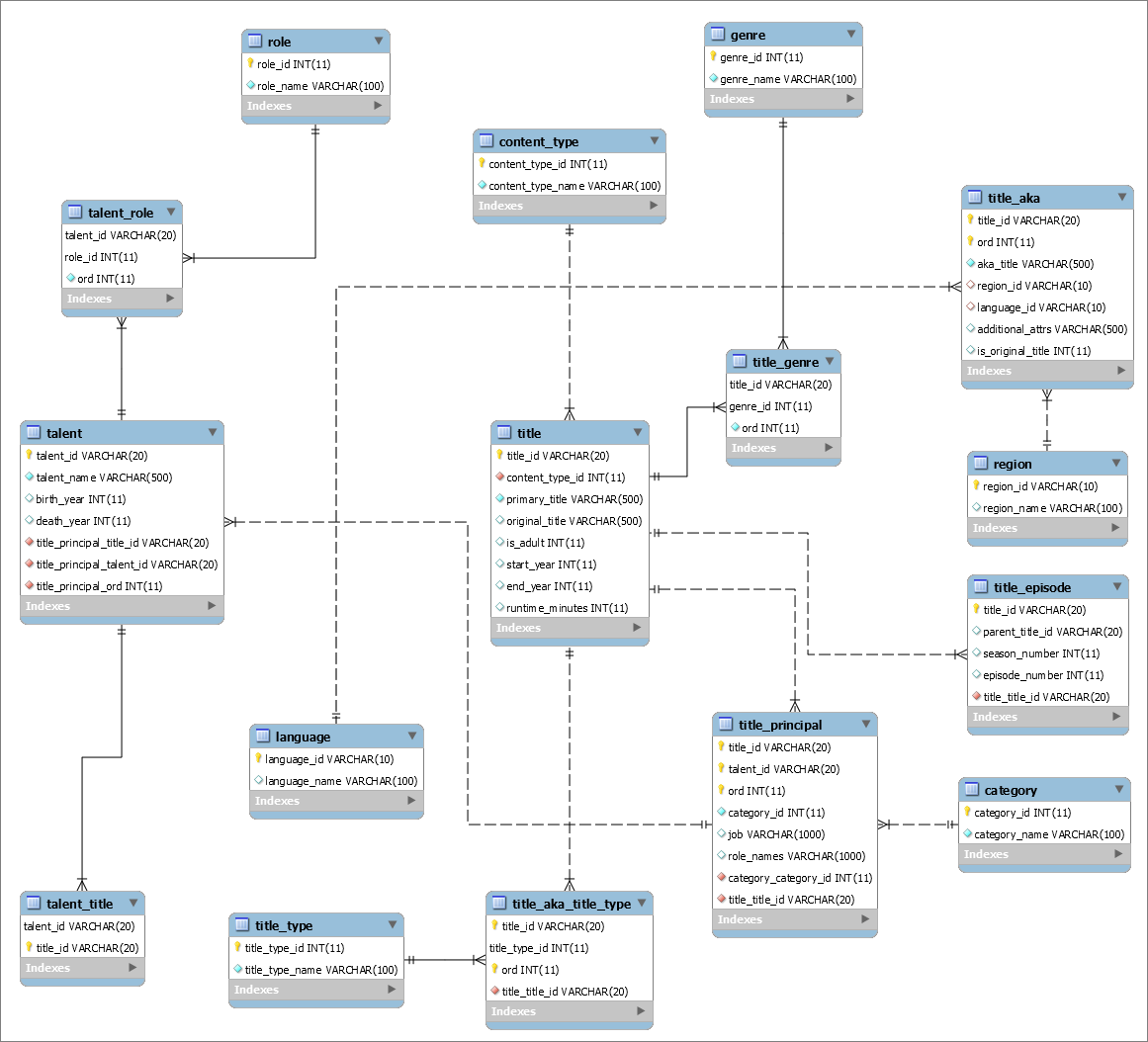
3. Data Loading
To load the raw data into a relational database schema, we will perform the following steps:
- Get the scripts we will be using from GitHub.
- Download the data files from IMDb.
- Run a Python script to re-arrange the data into a new set of files.
- Optional step: Run a Python script to extract a subset of the raw data.
- Load those new files into a database (we will use H2 and MySQL as examples).
H2 is a good choice if you don’t have MySQL available, and just want to get up-and-running quickly for demo or test purposes. See this post for a quick guide to installing and connecting to an H2 server and database.
This process assumes you have Python installed (I used Python 3.8).
3.1. Get the Scripts from GitHub
The github repository is here: relational-sample-imdb-data
Download the zip file of the repo to your PC, and unzip it. I will assume the files are in a new directory, with nothing else in it. I will assume this directory has been renamed to “imdb_test_data”.
Create a new directory “csv” in “imdb_test_data”.
Create a new directory “sampled” in “csv”.
3.2. Download the IMDb Files
The files are here:
I did this step manually. It’s a one-time process for me. I placed the files into the new directory from step 1:
3.3. Re-Arrange the Data
Open a command prompt, navigate to the imdb_test_data directory and run the following command:
python 01_process_imdb_files.py
This is a one-time process. It can take a while to run (approx. 60 minutes on my modest PC). I did nothing to optimize/parallelize how the job runs.
Running this script does the following:
- Unzips the IMDb source files.
- Processes each unzipped file in turn.
- Generates a new set of CSV files, containing re-arranged and normalize data.
- Places these new CSV files in the “csv” directory.
At the end of the process, you should see this:
![]()
And there will be the following new files in your “csv” directory:

3.4. Extract a Subset of Data
You may not wish to load the entire set of data into a relational database. It is approximately 100 million rows of data, in total.
You can optionally choose to run the 02_sample_titles.py script to create a second set of CSV files, containing a smaller sample of data:
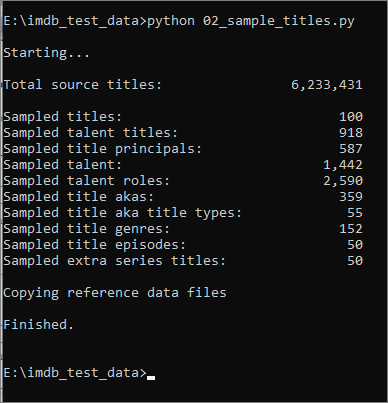
The files are placed in the “sampled” directory.
To control the sample size, edit the Python script’s “sample_size” variable.Read the related comments in the file!
3.5. Load the Data into a Relational Database
3.5.1. For loading into H2
At the command prompt navigate to the “h2” directory.
Execute the Windows batch script 01_run_data_load_script.bat. This connects to your H2 server (which must already be running, of course!), creates the schema and tables, and loads data from the sampled CSV files.
You may need to adjust the script, depending on the name and location of your H2 database.
3.5.2. For loading into MySQL
Navigate to the “mysql” directory and run the loader script. This is very similar to the H2 process - however, there are some additional considerations:
- You will need to edit the
my_conf.cnffile to provide the relevant credentials. - You will need to have created a user ID already in MySQL.
- MySQL expects upload files to be available in a specific location - see notes below.
- The user performing the upload will need permissions to read external data files, as well as the usual DDL and DML permissions.
MySQL Upload Files
You will need to copy your CSV data files to the secure upload directory referred to by the following MySQL command:
|
|
You may also need to increase the MySQL server parameter innodb_buffer_pool_size from its default value of 8 MB. Edit this setting in your server’s my.ini file, and then restart the server. Recommended: 64 MB. Check the current value with this command:
|
|
4. Final Warning
The data contains movies and videos for adult content titles. You can filter these out using the is_adult column in the title table. Do not use this data, or present it in demos, if that content may cause offense. Which it probably will. How you censor the data is up to you - but always be respectful of your audience.