
Tools for Displaying and Inspecting Unicode Data on Linux/Unix
First of all, if you can’t see the data properly, you’ll never really know what’s going on. So, make sure you’re able to display Unicode data correctly.
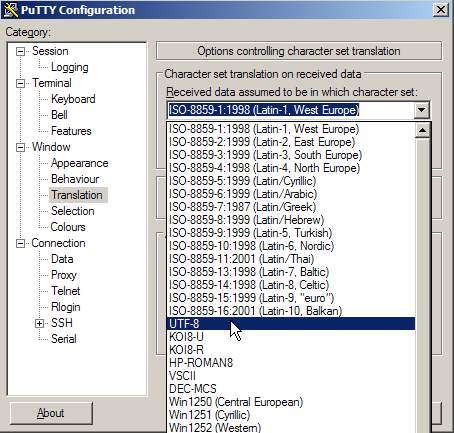
For example, let’s say you use PuTTY to access your server, make sure you’ve selected a suitable code page for character set translation:
You need to be comfortable inspecting the underlying bytes. If you’re working in a GUI then there are plenty of tools that will help you display the hex codes for your text data. If you’re at the command line, then here are two sample commands that will help:
hexdump -C
[test]$ hexdump -C testme.txt
00000000 44 6f 6e e2 80 99 74 20 e2 80 9c 71 75 6f 74 65 |Don...t ...quote|
00000010 e2 80 9d 20 6d 65 20 6f 6e 20 74 68 61 74 21 0d |... me on that!.|
00000020 0a |.|
00000021
[test]$
od -cx
[test]$ od -cx testme.txt
0000000 D o n 342 200 231 t 342 200 234 q u o t e
6f44 e26e 9980 2074 80e2 719c 6f75 6574
0000020 342 200 235 m e o n t h a t ! \r
80e2 209d 656d 6f20 206e 6874 7461 0d21
0000040 \n \0
000a
0000041
[test]$
iconv
The iconv command provides a convenient way to convert a file from one encoding to another:
iconv -f EBCDIC-US -t 8859_1 hello_ebcdic.txt > hello_88591.txt
You also need to understand how the settings displayed by the locale command work - and the implications of changing these settings.
When it comes to editing Unicode data, let’s take a look at vim. As a quick sanity-check, if vim supports the display and editing of Unicode data, you should be able to type :dig in command mode (short for :digraph) and see something similar to this:
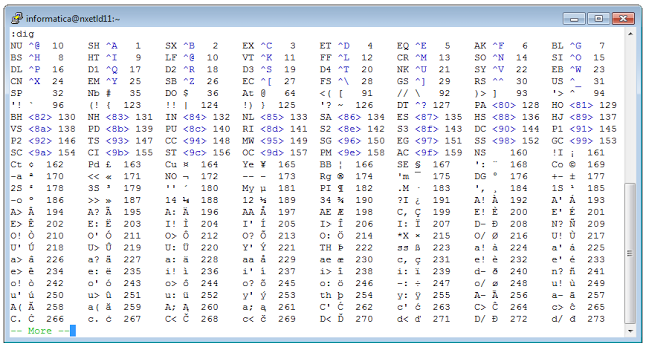
This table shows you all of the 2-character codes you can use to create symbols (or glyphs, or what you want to call them) in vi. For example, to create an e-acute, enter insert mode, type CTRL-K and then type the relevant characters - in this case e followed by an apostrophe (’).
If you understand Unicode, then you understand that, at heart, it’s a standard, not a code page. You understand that in its most basic definition it’s nothing more than the following three things: (1) a character (or glyph or grapheme); together with (2) a value that uniquely identifies that character; and (3) a more descriptive name for that character:

That’s it. OK - there are complications - for example, surrogate pairs handling in the Java language - but these are extremely rare (I am told).
Sticking with the above simpler concepts, when you encounter functions that manipulate a character based on its Unicode value (e.g. U+0061), it doesn’t matter how that character was encoded - you can be confident your function works as expected.
Final point - I always try to use UTF-8 wherever possible (which these days means everywhere), because it is the preferred encoding for Web content.