
Lucene 8.3 Basic Search Examples
Table of Contents
Introduction


My demo web application, which I describe here (with sources here), displays a core set of IMDb data:

But the application has a fatal flaw (maybe it has several, but I’m going to focus on one):
It doesn’t scale.
The IMDb data set I am using contains over 6 million title records (movies, TV episodes, etc). But my demo only handles a modest 5,000 of these, as highlighted above. Similarly, my IMDb data set contains over 9.6 million people (actors, directors, producers, etc.), and almost 36 million records to describe which people appear in which titles.
Within my web app, the 5,000 titles it does contain are all displayed in a single HTML table (albeit with client-side paging, courtesy of DataTables). But when that table is created, all 5,000 titles are sent from the server.
This is OK, given the purposes of my web app - to explore various technologies such as Javalin and Thymeleaf. But it’s not going to be practical in the real world, except for modestly sized data sets.
One solution already hinted at would be to introduce server-side paging: Fetch as much data as a user can see at one time, plus perhaps a little more. And then fetch the next chunk of data only if needed.
That may be necessary - but it’s probably not sufficient. Which brings us to the need for text searching.
Topics I will be covering in this post:
- My Lucene search utility
- Older Lucene versions and tutorials
- Introduction to Lucene 8
- My data sample
- Building indexes using analyzers
- Luke - the Lucene analysis tool
- Using my indexes
- How to run my sample code
- Faster performance?
- Typeahead and debounce
- Highlighting search terms in results
- Term vectors - (still not entrely sure when it’s best to use these)
- The custom analyzer
- Lucene alternatives
My Lucene Search Utility
I’ve never used Lucene’s API before - so I wanted to give it a try. Spoiler alert: I ended up with a small stand-alone application which uses typeahead to search all 6 million titles in my database:
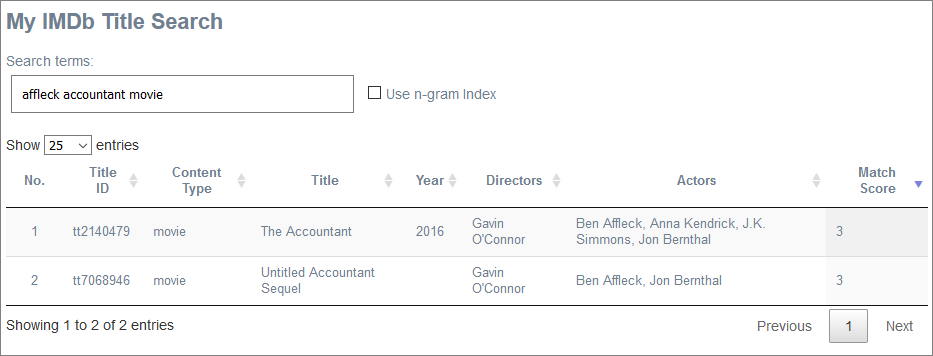
Now we know how it ends, let’s look at the rest of the story.
Older Lucene Versions & Tutorials
I am using the most up-to-date release - which at the time of writing is 8.3.0 (released November 2019).
I ran into issues with some of the existing tutorials, because the most prominent ones use older versions of Lucene, which no longer compile against 8.3.0.
Examples:
Baeldung - uses 7.1.0 (released October 2017)
LuceneTutorial.com - uses 4.0.0 (released October 2012)
Tutorialspoint - uses v3.6.2 (released December 2012)
Lucene versions 7.5.0 and 8.0.0 saw a reasonably large number of API changes, including some breaking changes in core classes (which - to be clear - were documented, and preceded by deprecation warnings in previous releases).
Examples of breaking changes in version 8 include:
-
LUCENE-8356: StandardFilter and StandardFilterFactory were removed.
-
LUCENE-8373: StandardAnalyzer.ENGLISH_STOP_WORD_SET was removed.
-
The default (no-arg) constructor for StopAnalyzer was also removed.
-
StandardAnalyzer.STOP_WORDS_SET was removed.
I also looked at Hibernate, which has a Lucene integration module (Hibernate Search). But the current version of that (5.11) uses Lucene 5.5.5, under the covers. And anyway, I wanted to use Lucene directly, to start with.
(I note that Hibernate Search 6 - currently in alpha - will include an upgrade of Lucene to version 8.2).
Lucene Resources
Other resources which helped me:
The Solr web site - a great place to look for definitions and terminology relating to Lucene (since Solr is built on top of Lucene). For example:
The ElasticSearch Reference web site can also help with terminology, for example:
I also looked at these sites - and although some of the code may be for older versions of Lucene, they were very helpful:
Introduction to Lucene 8
The best tutorial/resource I found for version 8 code was Lucene itself (surprise!). I downloaded the source code for the latest release from the “source release” link on this page:
https://lucene.apache.org/core/downloads.html
I then unzipped and untarred the file (lucene-8.3.0-src.tgz), and navigated to the demo directory:
…/lucene-8.3.0/demo/src/java/org/apache/lucene/demo
There, I took a look at IndexFiles.java, and SearchFiles.java, while reading the code overview provided here:
There’s lots more to explore on the Lucene web site - but this gave me a start.
And, of course, those other (older) resources are full of helpful training materials - just don’t expect their code to compile against the latest release. No doubt, someday my code will also fail to compile against a future Lucene release. So it goes.
My Data Sample
I already have a MySQL database containing the full set of IMDb data - see here for more info. For my indexing needs in this Lucene demo, I keep things very simple. I use a SQL query to assemble all the data I want to index: the title, the director, actors, content type, and year. I concatenate it all into a single field, for simplicity. This is tokenized, then placed in a Lucene document, along with the related title ID. There’s not much more to it than that.
In the next section I will look at how I split up this data into tokens, as the basis for building full-text indexes.
All of the code is available on GitHub here.
Building the Indexes Using Analyzers
I built two different indexes, using two indexing strategies. This was just to help me understand how the strategies affect the usefulness of each index for my searches.
This is a large topic - and one where I have barely scratched the surface. There is a daunting array of options for creating indexes, using different analyzers and filters.
To begin with, let’s look at the StandardAnalyzer. This may well be all you need.
|
|
This automatically uses:
StandardTokenizer, which splits text into words based on Unicode text segmentation rules (e.g. splitting on white spaces, and removing punctuation in the process).LowerCaseFilter, which does what the name suggests.- Removes stopwords.
For point (3): By default, the stopword list is empty. You can provide a list yourself, or use a predefined list from Lucene, or some combination of the above. For example:
|
|
I have further examples later on.
Here is a StandardAnalyzer example taken directly from the official Unicode text segmentation document:
Input text: The quick ("brown") fox can't jump 32.3 feet, right?
After processing by the Lucene standard analyzer, we have the following tokens available to be indexed:
the, quick, brown, fox, can't,jump, 32.3, feet, right,
Here are the two analyzers I created. Each analyzer represents a set of transformations to be applied to my raw data, before the data is indexed:
My SimpleTokenAnalyzer:
|
|
In the above analyzer (full code here), my input data is converted to lower case, then stop-words are removed, and finally accents are removed (along with other ASCII folding mappings). The resulting string of text is then split into a set of tokens (as described above) - and each token is indexed.
Here is the second:
My Ngram35Analyzer:
|
|
The above analyzer (full code here) excludes stopword removal, but includes an extra step: It splits the output into ngram tokens, between 3 and 5 characters in length. For example, the word hello is split into the following tokens for indexing: hel, ell, llo, hell, ello, hello.
One advantage of using ngrams is that we can now search using partial words - without needing a wildcard at the beginning of our search term (which would defeat the purpose of having an index in the first place). This means that the index would allow us to enter father as our search term, and would find titles containing godfather, grandfather, fatherhood and so on.
Of course, this means we are indexing more data than in our first example (where hello was simply indexed as hello).
See later in this post for step-by-step instructions on using my code to build the above two indexes.
Luke - The Lucene Analysis Tool
In both cases, I created my index data in a filesystem directory (see the IndexBuilder class). One advantage of this is that I can point Luke at this directory and explore the index data.
Luke is an analysis tool for Lucene. It’s available as a JAR file (lucene-luke-8.x.x.jar), which can be found in the main Lucene binary release package (downloadable from this page).
Run the luke.bat or luke.sh script provided with the JAR to launch Luke. Then point Luke at your index directory:
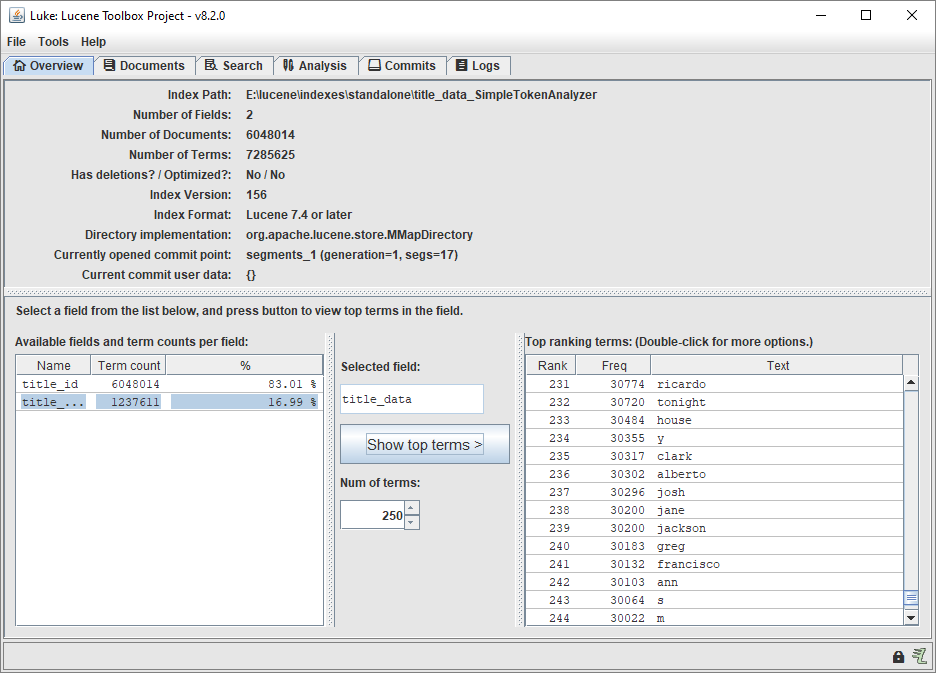
This is a great way to explore the data.
In the above screenshot, you can see that there are two fields in each of my indexed documents:
- title_id
- title_data
Again, my implementation is very basic: When creating the indexes, I concatenated together all of the data I wanted to index (title, actors, etc). That data was tokenized, and stored in the title_data field in my index. Note that the original data is not stored - just the data after being converted to tokens by my analyzer (you can see that in the code here).
I also store the title ID in each indexed document - because that is the primary key value which will allow me to join my index results back to the rest of my relational data. More on that below.
Using the Indexes
When I enter a search term in my web page, a two-step process is executed:
-
Lucene inspects my index data, finds matches for my search term, and ranks them from most relevant downwards (it provides a matching score for this). Lucene returns a set of results, which includes the title_id I stored alongside my indexed data.
-
My code takes the title_id from each Lucene result and executes a SQL query to retrieve the relational data for the top 100 matched results. It uses a simple prepared statement to do this, of the form:
|
|
Those results are then presented back to the user.
This is far from the only way to use Lucene search results - in fact it’s probably the most basic. For example, with a more structured Lucene index document (one which doesn’t concatenate all my indexable data into only one field), it could be possible to avoid step 2 altogether.
Using My Sample Code
My sample code consists of a web server (based on Javalin) and a client web page where searches are initiated and results are displayed (provided by a stand-alone HTML text file).
Search results are sent from the server to the client via JSON - Javalin has built-in support for this which makes the process straightforward.
Before building and running the server, you will need to make two changes to the code:
-
Provide the location of a new empty directory, here and here (sorry, same thing in 2 places) - this is where Lucene will store and access its indexing data.
-
Provide your database’s credentials for access to the IMDb data (assuming you have already set that up). My code assumes you are using a MySQL database.
Build and run the web server using the usual Maven commands (not discussed here).
To build the SimpleTokenAnalyzer index, open a web browser and go to the following URL:
http://localhost:7000/build_index/simple
Progress will be shown in the output terminal of the server process. The process takes approximately one hour on my PC. At the end, you should see something like this:
17:20:35.519 [INFO ] - Starting - simple index will be built...
...
18:14:18.451 [INFO ] - Indexed 6,030,000 documents
18:14:18.451 [INFO ] - Approx 0 minutes remaining
18:14:22.964 [INFO ] - Indexed 6,040,000 documents
18:14:22.964 [INFO ] - Approx 0 minutes remaining
18:14:27.088 [INFO ] - Indexed 6,048,014 documents in 54 minutes
18:14:27.088 [INFO ] - at a rate of approx. 1,875 documents per second.
18:14:27.088 [INFO ] - Finished.
The final index consists of 338 MB of data.
To build the Ngram35Analyzer index, use this URL:
http://localhost:7000/build_index/ngram
The output will again take about an hour:
18:16:55.495 [INFO ] - Starting - ngram index will be built...
...
19:17:19.462 [INFO ] - Indexed 6,030,000 documents
19:17:19.462 [INFO ] - Approx 0 minutes remaining
19:17:24.383 [INFO ] - Indexed 6,040,000 documents
19:17:24.383 [INFO ] - Approx 0 minutes remaining
19:17:29.195 [INFO ] - Indexed 6,048,014 documents in 60 minutes
19:17:29.195 [INFO ] - at a rate of approx. 1,667 documents per second.
19:17:29.195 [INFO ] - Finished.
This index is much larger - 1.83 GB of data (a consequence of my ngram configuration choices).
Faster Performance
Lucene is capable of much faster indexing speeds than those shown above - my index creation process is basic: One document at a time. That’s about the slowest approach of all.
The Lucene source code package (where the basic demo code is provided) includes examples of how to optimize Lucene performance.
For example, Lucene can index multiple documents placed in one file. See the WriteLineDocTask.java example here:
.../lucene-8.3.0/benchmark/src/java/org/apache/lucene/benchmark/byTask/tasks/WriteLineDocTask.java
As with Analyzers and Filters, this is a very large topic - and outside the scope of this simple post.
Typeahead and Debounce
The client web page I am using in this demo uses a typeahead technique: As the user types a search term into the input field, that data is sent to the server via an AJAX call, and results are returned while the user is still typing.
This feature is sometimes seen in autocomplete situations, such as drop-down lists: The user has a drop-down list of country names. The list shrinks, as the user types more text.
Because the user’s search data is sent to the server via a DOM keyup event, it is possible for multiple events to be generated in rapid succession. The debounce library…
|
|
…is used to ensure that only one event is submitted to the server every 300 milliseconds at most. 300 is a good value for my environment - it may not be suitable in other environments.
(There is also this typeahead.js library - which I have never used. And probably others, too.)
Just to be clear - there is no need to use typeahead with Lucene. They are two separate concepts.
Highlighting Search Terms in Results
One thing not included in my lookup utility is Lucene’s ability to highlight search terms in search results. This can be useful in helping a user to understand why a record was returned by a search - especially if the data being returned is a large document rather than a small database record.
The following sample shows the core of how Lucene handles highlighting. It assumes that the data being highlighted is included as part of the index (the simplest case):
|
|
The above code also assumes that text is being highlighted for display in HTML - hence the use of a span and a class to control the appearance of highlighting.
Highlighting for simple text searches is straightforward - and you may even consider applying it outside of Lucene altogether. But for more complicated searches and complex analyzers (e.g. overlapping search terms, wildcards, regular expressions, and other customizations), it can become challenging.
Also, if your raw data is not stored alongside your indexed data in a Lucene index, then in my above example this line:
|
|
will return a null value. In this case, Lucene will require additional data (term vector information) in order to find the correct location of the data to be highlighted.
That is outside the scope of this article - because I am still figuring out what term vectors are and how and when they should (and should not) be used.
Term Vectors
When you create a document for indexing, you must give each field in the document a name, and you must indicate what type of data it is, from a set of Lucene data types (text, numeric, date, etc).
So, in my lookup utility, I have a simple document defined as follows:
|
|
However, you can also choose to create document fields with additional term vector attributes:
|
|
What is this data? Luke can show us:
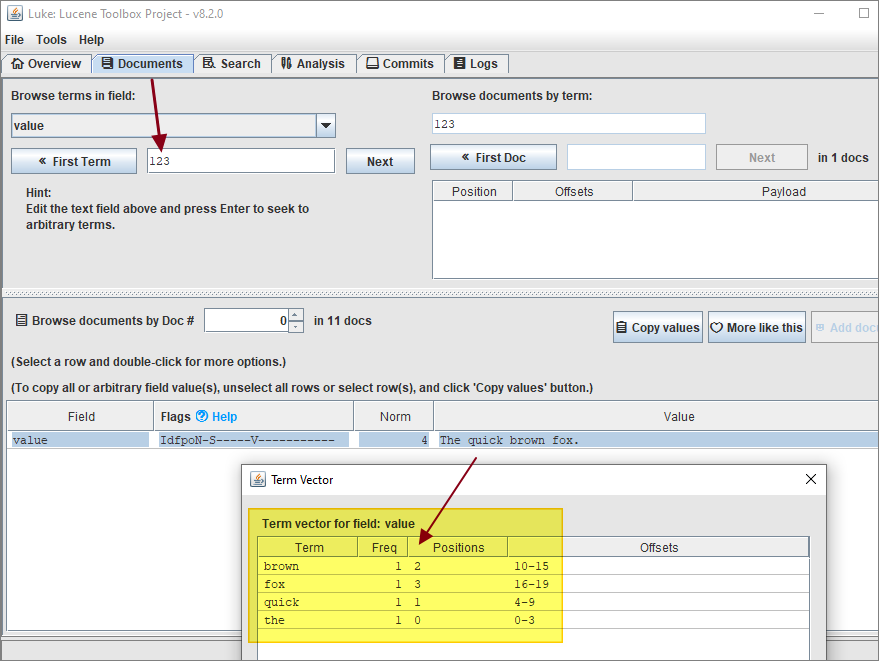
As we can see, it is a set of frequencies, positions, and offsets for each indexed tern.
In my earlier CustomHighlighter example, I could have accessed term vector data as follows (assuming term vector data had been specified when the index document was defined, of course):
|
|
The Custom Analyzer
In my demo lookup service, I used two analyzers: SimpleTokenAnalyzer and Ngram35Analyzer. I used class references to assemble the various analyzers, tokenizers and token filters I wanted to use.
But there is an alternative approach which uses the CustomAnalyzer class, together with the builder pattern, to provide a more expressive way to define analyzers. An example:
|
|
Valid names (“lowercase” etc.) are available from the NAME field of the related builders.
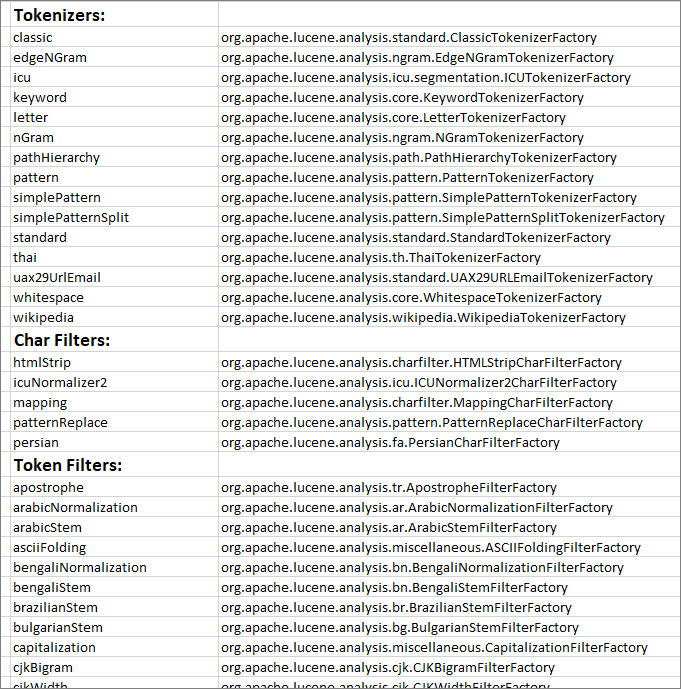
If you want a cheat sheet of all names, then one can be generated using the following code:
|
|
And the output (pasted into Excel) looks like this:
Lucene Alternatives
My Lucene indexes allow me to provide full-text search functionality across all 6 million of my IMDb titles - it even supports “immediate feedback” searches through its implementation of typeahead.
My demo is limited, of course. There is no logic to maintain the index, if data changes. But that was not the objective of this modest demo.
There are alternatives to Lucene.
As has already been mentioned, Lucene is available via Hibernate. This may be a good choice if you already use Hibernate.
Lucene is used in Solr. Whereas Lucene is essentially a Java library (albeit a very large and sophisticated library), Solr is a fully-fledged application sitting on top of Lucene. As such, it can - among other things - help with the management of your Lucene infrastructure. The more I look at Lucene, the more that appears to be a potentially complex undertaking.
Elasticsearch - beyond knowing that it exists, and is also based on Lucene, I don’t know enough about it to comment. Worth mentioning: Kibana is a data visualization tool for Elasticsearch.I’ve used it briefly and it looked impressive.
You may also get what you need from using text search capabilities built into your RDBMS. MySQL is one example, although the search options and syntax are relatively limited compared to Lucene.