
Lucene 8.3 - More Analyzers - and Some Queries
Table of Contents

Introduction


While I was exploring Lucene as a way to improve my demo web application, I tried a few different combinations of analyzers, tokenizers and filters. It got to the point where I created a small test application for this.
The code is available in GitHub.
In this article I will be looking at two different approaches to writing queries in Lucene - so I want to be clear about what these are.
Classic Query Parser
This lets you write a Lucene query as a string of text, using its query parser syntax. For example:
((+value:quick +value:jump) value:quick jump)
Details can be found in the relevant JavaDoc for the queryparser.classic package.
Lucene Query API
This involves building queries using Lucene query classes. There are many different classes depending on the type of query you want to construct - but they are often wrapped in a BooleanQuery object:
|
|
Standard Query Parser
For completeness, there is a third approach: The Standard Query Parser, which is based on the Classic Query Parser, but written to be more flexible and modular. This is not discussed here - but you can read more about it in the JavaDoc for the `StandardQueryParser class.
Lucene Analyzer Tester
You will need to choose a directory location for index data.
Run the application (after building it using Maven, in the usual way), and point your browser here:
http://localhost:7000/testresults
A suite of tests is run, and the results are displayed in the web page - for example:

It’s easy to add new analyzers, and to add new tests for each analyzer:
-
Create a new analyzer - there are several examples in the analyzerspackage already.
-
Add whatever tests you want to your new analyzer class (again, see the existing analyzer classes for examples).
-
Add the new analyzer to the Tester.inputs()method - which collects all the tests to be executed.
This could have been created as a jUnit test suite (I would call these “integration” tests, rather than unit tests). But I wanted to highlight my matches, to better understand the results. Displaying the results in a web page made the highlights easier to review.
This process helped me to understand the basic capabilities of each step in the analysis chain.
When I looked at the results from the shingle-based analyzer, however, I was caught by surprise:

The above example shows zero matches, using the following query:
((+value:quick +value:jump) value:quick jump)
I had read in this pagethat the OR operator is the default operator. Specifically:
“The OR operator is the default conjunction operator. This means that if there is no Boolean operator between two terms, the OR operator is used.”
I therefore interpreted my query to mean this..
((+value:quick OR +value:jump) OR value:quick jump)
…where the + indicator makes a term mandatory (“MUST” be found).
But that clearly was not working the way I expected. Why were there no hits?
Lucene So-Called Boolean Queries
It turns out that Lucene has a lot more going on than traditional boolean operations.
Remember - Lucene provides a set of results, ranked by score. And that should be a big clue that we’re not talking about simple “hit or miss” searching, here. This is a tangibly different process than the one used, for example, in the WHERE clause of a traditional SQL statement.
The beginnings of insight came when I read the following two articles:
- Solr and Boolean Operators (in which the “principle of least surprise” is truly broken)
- Boolean Operators for Solr Users ("why not
and,orandnot", indeed!)
Both refer to Solr, but the principles apply to Lucene.
As the second article explains, a Lucene boolean query is a set of Lucene BooleanClauses.
And a BooleanClause consists of:
- A nested
Query. - A related
BooleanClause.Occurflag, with one of the following values:
MUST- for clauses that must appear in the matching documentsMUST_NOT- for clauses that must not appear in the matching documentsSHOULD- for clauses that must appear in the matching documentsFILTER- same asMUSTbut clauses do not participate in scoring
For our (+value:quick +value:jump) example, the + notation means MUST, and that isn’t an implied boolean “or” in between the two terms (because that would not make any sense) - it’s really an “and”. And it’s still not a “boolean and” - it doesn’t perform that operation.
Classic Boolean Operator Rules
There are also so-called boolean operators in Lucene (AND, OR, NOT). But they have really odd characteristics - again, summarized from the second article above, where the behavior is described as “bizarrely esoteric”:
| No. | Operator | Rule |
|---|---|---|
| 1 | all | Queries are parsed left to right. |
| 2 | NOT |
NOT sets the Occurs flag of the clause to its right to MUST_NOT. |
| 3 | AND |
AND sets the Occurs flag of the clause to its left to MUST, unless it has already been set to MUST_NOT. |
| 4 | AND |
AND sets the Occurs flag of the clause to its right to MUST. |
| 5 | OR |
If the default operator of the query parser has been set to AND, then OR sets the Occurs flag of the clause to its left to SHOULD - unless it has already been set to MUST_NOT. |
| 6 | OR |
OR sets the Occurs flag of the clause to its right to SHOULD. |
Additional notes:
The symbol
||can be used in place of the wordOR.The symbol
&&can be used in place of the wordAND.The symbol
!can be used in place of the wordNOT.The
+operator is used to indicate a required term.The
-operator is used to indicate a prohibited/excluded term.
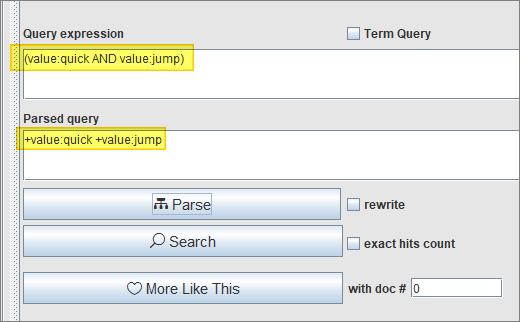
So, in our case, a query such as this:
(value:quick AND value:jump)
…is actually this:
(+value:quick +value:jump)
And this:
(value:quick OR value:jump)
…is actually this:
(value:quick value:jump)
If in doubt, use Luke to double-check what’s going on:
When things are strange like this, the chances are they are even stranger than you think.
More practically, things may behave differently now from how they did in previous releases (and may behave differently again in the future).